- März 29, 2022
- Patrick Minder
Um dieser Frage nachzugehen, gehen wir in diesem Beitrag auf unsere Systeme für die Echtzeit-Überwachung von Pollen ein. Wir zeigen auf, welche Pollensorten SwisensPoleno aktuell identifizieren kann. Zusätzlich erfahren Sie, welche Möglichkeiten und Wege bestehen, sollte die von Ihnen gewünschte Pollen-Taxa nicht auf der Liste stehen. Bevor wir an das Eingemachte gehen, hier ein kurzer Exkurs wie SwisensPoleno Mars die verschiedenen Partikel und Pollentypen von einander unterscheidet.
Pollen identifizieren mit Supervised Machine Learning
SwisensPoleno Mars misst jedes einzelne Partikel und erfasst die morphologischen Eigenschaften. Das System tut dies, in dem es zwei holographische Bilder von jedem gemessenen Partikel im Flug erfasst. Diese Bilder zeigen die charakteristischen Formen und Grössen der Pollen, die die künstliche Intelligenz von SwisensPoleno Mars zur Erkennung nutzt. Gleiches gelingt auch uns Menschen recht gut, obwohl die holographischen Bilder der Pollen anders aussehen, wie wenn wir sie unter dem Mikroskop betrachten.
SwisensPoleno Jupiter hingegen enthält zusätzliche Messmethoden und kann weitere Eigenschaften eines Partikels messen. In der Praxis hat sich jedoch gezeigt, dass die KI viele Pollentypen anhand der holographischen Bilder sehr gut unterscheiden kann. Insofern kann man sagen, dass SwisensPoleno Mars für die Pollenüberwachung in Echtzeit in den meisten Fällen ausreichend ist. In diesem Artikel beziehen wir uns fortan nur noch auf die Pollenerkennung mit SwisensPoleno Mars.
Erfahren Sie mehr über den Unterschied von SwisensPoleno Mars & Jupiter.
Was muss ich unter künstlicher Intelligenz verstehen?
Sprechen wir von künstlicher Intelligenz, meinen wir damit konkret «Supervised Machine Learning». Dazu folgt nun eine kurze Erklärung über dessen Grundprinzip:
„Supervised Machine Learning ist ein Prozess des maschinellen Lernens, wo einem Algorithmus ein Datensatz mit bekannter Zielvariable vorgelegt wird. Der Algorithmus erlernt die Zusammenhänge und Abhängigkeiten in den Daten, welche diese Zielvariablen erklären. Nach Ablauf des Trainings wird die vom Algorithmus erstellte Vorhersage auf deren Qualität bewertet. Anschliessend werden die erlernten Muster auf unbekannte Daten angewendet um Vorhersagen zu erstellen (Datasolut, 2022).“
In unserem Fall soll SwisensPoleno Mars die verschiedenen Pollentypen voneinander unterscheiden können. Dazu trainieren wir den Algorithmus mit einem Datensatz, welcher ausschliesslich aus Partikeln einer bestimmten Pollensorte (z.B. Birke bzw. Betula pendula) besteht. Wir sprechen dann von einem Trainingsdatensatz. Diesen Trainingsdatensatz erzeugen wir, in dem wir frische Birkenpollen sammeln und danach mit dem System messen. Dazu werden die Pollen mit Hilfe des SwisensAtomizer am Einlass des SwisensPoleno Mars zerstäubt währenddessen das System läuft und misst. Dank diesem Trainingsdatensatz erlernt der Algorithmus, Betula pendula zu erkennen, beziehungsweise korrekt zu identifizieren. Den genau gleichen Ablauf führen wir mit weiteren Pollensorten durch. Am Ende des Trainings ist die künstliche Intelligenz von SwisensPoleno Mars bereit, die trainierten Pollensorten automatisch in Echtzeit zu erkennen und zu überwachen.
Welche Pollen kann SwisensPoleno Mars aktuell identifizieren?
Aktuell zählt unsere Liste 14 verschiedene Pollensorten, wie in der nachfolgenden Tabelle aufgelistet. Im Fokus stehen die Pollen, welche für Personen mit einer Pollenallergie in Zentraleuropa relevant sind.
| Nr. | Taxa lat. | Nr. | Taxa lat. | Nr. | Taxa lat. | Nr. | Spezial |
| 1 | alnus | 6 | fagus | 11 | populus | 15 | Wasser |
| 2 | betula | 7 | fraxinus | 12 | quercus | ||
| 3 | carpinus | 8 | pinaceae | 13 | taxus | ||
| 4 | corylus | 9 | platanus | 14 | ulmus | ||
| 5 | cupressus | 10 | poaceae |
Die Algorithmen für diese 14 Pollensorten sind validiert und laufen auf all unseren Systemen in Zentraleuropa. Dies trifft zum Beispiel für die Länder Schweiz, Deutschland, Frankreich, Finnland, Litauen, Spanien und Grossbritannien zu. Wie in der Tabelle ersichtlich, gibt es noch eine weitere Klasse für Wassertropfen (Nummer 15). Hier erklären wir kurz warum:
Kann SwisensPoleno neben Pollen auch Wassertropfen identifizieren?
Tatsächlich misst und erkennt SwisensPoleno Mars problemlos Regentropfen und zeigt auf, an welchen Tagen es geregnet hat. Der eigentliche Grund für die Klasse «Wasser» ist aber ein anderer. In der Vergangenheit haben die Algorithmen Regentropfen fälschlicherweise als Gräserpollen klassifiziert. In der nachfolgenden Abbildung sehen Sie je ein Beispiel eines Gräserpollenkorns und eines Wassertropfens. Die Ähnlichkeit von Grösse und Form in den holographischen Bildern ist sofort erkennbar. Der Algorithmus kann nun dank der zusätzlichen Partikel-Klasse «Wasser» diese problemlos voneinander unterscheiden. Doch nun zurück zu den Pollen.

Warum funktionieren die Algorithmen nur für Zentraleuropa?
Der Hauptgrund ist, dass es in anderen Regionen unserer Erde andere Pflanzen und Pollen gibt, die Allergien verursachen. Im Algorithmus für Zentraleuropa fehlen diese. Der Algorithmus muss also angepasst werden.
Sind dieselben Pollen anderswo nicht genau gleich?
Diese Frage kann derzeit noch nicht beantwortet werden, weil man das noch nicht abschliessend untersucht hat. Beobachtet wurde, dass je nach Land oder Region die gleichen Pollensorten zum Beispiel in der Grösse leicht variieren. Insofern kann das dazu führen, dass diese Pollen weniger gut oder gar falsch klassifiziert werden. So bestehen zum Beispiel die Gräserpollen (Poaceae) aus einer Pflanzenfamilie von ca. 780 Gattungen und 12000 Arten, die morphologische sehr ähnlich sind, aber in jedem Land einen unterschiedlichen Mix bilden.
Um gleichwohl die Qualität der Echtzeitdaten sicher zu stellen, lohnt es sich, die Algorithmen auf die lokale Flora anzupassen. Konkret bedeutet dies, Datensätze von lokalen Pollen zu erzeugen und die Algorithmen damit zu trainieren. Dieses Vorgehen empfehlen wir typischerweise während der ersten Pollensaison mit dem neuen Echtzeit-Messsystem und leiten damit zum nächsten Abschnitt über.
Wie kann SwisensPoleno Mars auf die lokale Flora trainiert werden?
SwisensPoleno Mars kann für die Identifikation von zusätzlichen Partikeln und Pollensorten trainiert werden. Dazu haben wir einen Prozess entwickelt (siehe nachfolgende Abbildung).
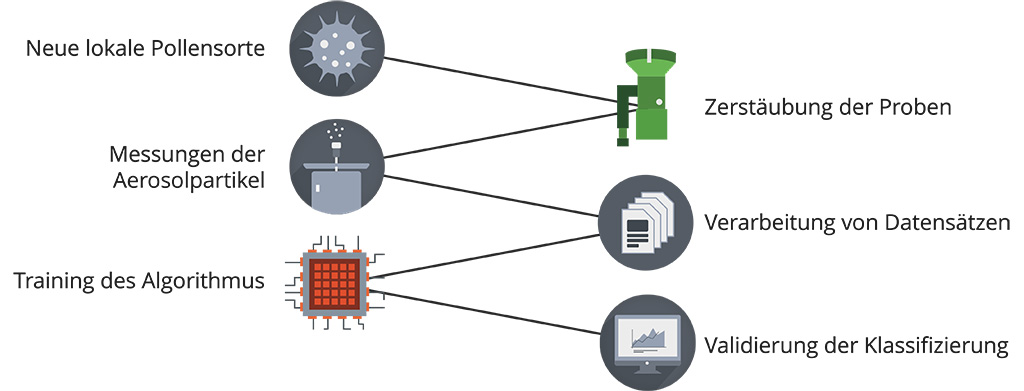
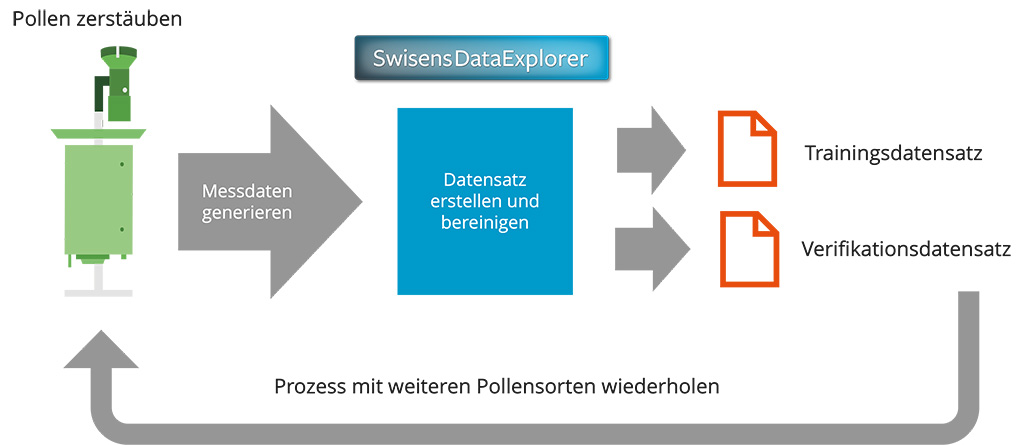
Der Erweiterungsprozess dauert eine Pollensaison lang und muss einmalig durchgeführt werden. Idealerweise fängt man mit dem Start der neuen Pollensaison an und sammelt frische Pollen einer Pollensorte, die das System identifizieren soll. Eine Menge von 0.3ml (oder ca. 0.1g) ist völlig ausreichend. Um den Trainingsdatensatz zu erzeugen, muss das Messsystem die Partikel aus der Luft ansaugen. Dazu muss ein Aerosol erzeugt werden – ein Gemisch aus Schwebeteilchen in einem Gas. Mit Hilfe des SwisensAtomizer werden die Pollen aus einer Makrovolumen-Cuvette kontrolliert in die Luft zerstäubt und anschliessend von SwisensPoleno Mars angesaugt.

Weil die gesammelten Pollen typischerweise nicht rein sind, manchmal zwei Pollenkörner aneinander kleben oder die Luft Fremdpartikel enthält, müssen die gemessenen Daten im Anschluss gereinigt werden. Das geht einfach und schnell mit den Softwaretools von Swisens wie zum Beispiel dem SwisensDataExplorer. Dieses Werkzeug wird mit dem Instrument mitgeliefert. Im nächsten Schritt werden die Messdaten in zwei Datensätze (Trainingsdatensatz und Verifikationsdatensatz) aufgeteilt und für das Training verwendet.
Je sauberer der Trainingdatensatz ist, desto besser funktioniert das Training und der Identifikationsalgorithmus. Diesen Prozess gilt es für jede Pollensorte, die das System erkennen können soll, durchzuführen.
Der SwisensPoleno Mars nutzt nur die holographischen Bilder für die Erkennung. Obwohl alle Systeme genau gleich aufgebaut sind und sich selbst kontinuierlich neu kalibrieren, sind die einzelnen Bauteile gewissen Toleranzen unterworfen, welche zu minimalen Unterschieden in den Bildern führen können. Darum kann die Generalisierung noch erhöht werden, wenn man Trainingsdaten mit zwei Systemen generiert.
Die gewonnenen Trainingsdatensätze verwenden wir für den maschinellen Lernprozess um den neuen Identifikationsalgorithmus zu trainieren. Zur Qualifizierung muss der trainierte Algorithmus Pollensorten aus einem unbekannten Datensatz erkennen. Dazu dient der Verifikationsdatensatz. Das Resultat ist eine so genannte Konfusionsmatrix. Diese gibt Aufschluss über die Genauigkeit des neuen Algorithmus.
Wie kann man die Qualität eines neuen Algorithmus überprüfen?
Für die Validierung eines neuen Algorithmus sollte neben einem SwisensPoleno Mars als Referenz eine Hirst-Pollenfalle parallel sowie in unmittelbarer Nähe eine Saison lang betrieben werden. Die von SwisensPoleno Mars über die Pollensaison hinweg aufgenommenen Messdaten werden am Ende der Saison mit dem neuen Algorithmus reklassifiziert. Als Resultat liegen Zeitreihen mit den Konzentrationen der verschiedenen Pollensorten vor. Die Zeitauflösung wird gleich gewählt wie die der Referenzdaten der Hirst-Pollenfalle. Typischerweise ist das eine Tagesauflösung. Die Zeitreihen vom SwisensPoleno Mars und der Hirst-Pollenfalle werden anschliessend miteinander verglichen und die Korrelation bestimmt.
Braucht jeder SwisensPoleno einen eigenen Algorithmus um Pollen zu identifizieren?
Nein – das gesamte Verfahren muss nur einmalig auf einem (oder zwei) SwisensPoleno Mars durchgeführt werden. Die damit trainierten Algorithmen können auf die anderen Systeme im Netzwerk übertragen werden. Swisens bietet Expertise an, um die Algorithmen mittels des beschriebenen Verfahrens auf die lokale Flora anzupassen und die Kunden im Prozess zu unterstützen.
Was ist das Endergebnis nach der ersten Pollensaison mit SwisensPoleno Mars?
Am Ende der ersten Pollensaison stehen lokale Pollenalgorithmen zur Verfügung. Ab diesem Zeitpunkt überwacht, respektive identifiziert SwisensPoleno Mars die Pollen automatisch und in Echtzeit. Wenn die Messdaten gespeichert sind, können diese so oft mit einem neuen Algorithmus reklassifiziert werden, wie gewünscht. Eine Reklassifikation mit einem neuen Algorithmus auf Basis der Rohmessdaten ist sowohl für die Daten aus einer einzelnen Messstation, als auch für das gesamte Netzwerk jederzeit möglich.
Gibt es einen weiteren Nutzen der Reklassifikation?
Es kann vorkommen, dass während der ersten Pollensaison noch nicht von allen relevanten Pollensorten Trainingsdaten erzeugt werden können. Sobald die noch fehlenden Trainingsdaten in der darauffolgenden Pollensaison aufgenommen wurden, kann ein neuer Identifikationsalgorithmus erzeugt, und die bereits vorhandenen Messdaten aus der vergangenen Saison damit reklassifiziert werden. Eine Validation mit den Referenzdaten der letztjährigen Saison über alle relevanten Pollensorten ist damit ohne weitere Verzögerung möglich. An dieser Stelle kommen wir wieder auf die eingangs gestellte Frage zurück:
Kann SwisensPoleno nun die Pollen in meiner Region identifizieren?
Wir sagen JA!
Unsere Entwicklungsabteilung arbeitet täglich an der Weiterentwicklung neuer Algorithmen. Hinzu kommt, dass wir eine stetig wachsende Partikel-Datenbank mit Datensätzen für Trainings führen. Es kann also gut sein, dass für Ihr Land bereits regional angepasste Algorithmen existieren. Kontaktieren Sie uns falls Sie es genauer wissen möchten. Gerne bieten wir Ihnen Hand und unterstützen Sie wo wir können!