- Mai 22, 2022
- Yanick Zeder
Die künstliche Intelligenz von SwisensPoleno setzt einen Vorfilter zur Trennung verschiedener Partikelkategorien ein. Was es mit dem Vorfilter für die automatische Pollenidentifikation auf sich hat, erklären wir in diesem kurzen Blog-Artikel. Dabei beantworten wir folgende Frage:
Wie unterscheidet SwisensPoleno Pollen von anderen Aerosol-Partikeln?
Das Problem der Vielfältigkeit
Vorweg beginnen wir mit ein wenig Hintergrundwissen. Bei der Messung von Aerosol-Partikeln stellen wir ziemlich schnell fest, wie viel Material in der Luft herumfliegt. Wie in Abbildung 1 dargestellt, gibt es alle Arten von Staub, Verbrennungsrückstände, Pollen, Sporen, Bakterien und vieles mehr. Diese Mischung aus Aerosol-Partikeln ist stark von den Umweltbedingungen abhängig und kann unter anderem von der Region, der Tageszeit, dem Wetter und der Jahreszeit abhängen. In den meisten Fällen machen Pollen nur einen sehr geringen Anteil an der Gesamtmischung aus.
Ein Echtzeit-Aerosolmesssystem wie SwisensPoleno hat nun die anspruchsvolle Aufgabe, die Daten aus einer vielfältigen und sehr heterogenen Mischung, sinnvoll zu verarbeiten und einzelne Partikel-Klassen zu erkennen. Zum Beispiel für die automatische Pollenidentifikation in Echtzeit. Genau für eine solche Anwendung kommen bei uns Klassifikationsalgorithmen ins Spiel. Wie ein solcher Klassifizierungsalgorithmus funktioniert, erklären wir im nächsten Abschnitt.
Was macht ein Klassifizierungsalgorithmus?
Nachdem wir nun die Voraussetzungen geschaffen haben, müssen wir ein grundlegendes Verständnis für einen Klassifizierungsalgorithmus aufbauen. Da wir mit diesem Thema ganze Bücher füllen könnten, versuchen wir hier nur einen groben Überblick zu geben.
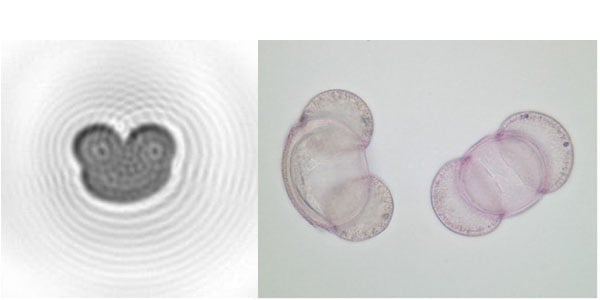
Der Algorithmus von SwisensPoleno nimmt die Messdaten, betrachtet diese und erklärt im Anschluss zu welcher Klasse die gemessenen Aerosol-Partikel gehören. Eine Klasse kann dabei einem bestimmen Pollentyp (z.B. Pinus) entsprechen. Um dies zu bewerkstelligen, wurde ihm mehrere tausend Trainingsdaten für die Klasse «Pinus» vorgelegt. Im Wesentlichen sucht der Algorithmus nach Merkmalen, die die Daten dieser Klasse charakterisiert. Bei einer ausreichenden Anzahl von Trainingsdaten, erkennt der Algorithmus, dass Pinus-Pollen eine herzförmige Form mit einer bestimmten Größe und Ausrichtung haben, wie in Abbildung 2 dargestellt. Nach diesem Trainingsprozess können wir dem Algorithmus neue Daten geben, um diese selbstständig zu klassifizieren. Durch den Abgleich der im Training gefundenen Merkmale mit den neuen Daten, ermittelt der Algorithmus eine Wahrscheinlichkeit. Diese Wahrscheinlichkeit sagt aus, inwiefern die neuen Daten zu der antrainierten Beispielklasse gehören. Im Beispiel in Abbildung 2 (rekonstruiertes Holographiebild von Pinus, links) würde der Identifikationsalgorithmus vielleicht Pinus mit 98%iger Sicherheit Pinus, Fagus mit 2%iger Sicherheit Fagus und mit dem Wert „Null“ für die restlichen Klassen ausgeben.
Was passiert, wenn wir dem Algorithmus Daten von einem Aerosol-Partikel zeigen, für das er noch nie Beispiele gesehen hat? Der Algorithmus wendet dasselbe Verfahren an wie bei jedem anderen Partikel zuvor. Er gleicht die gefundenen Merkmale mit den neuen Daten ab. Vielleicht weist eine Klasse einige Ähnlichkeiten auf, und der Algorithmus ordnet sie dieser Klasse zu. Dies kann zu einer falschen Klassifizierung führen. Er hat eine Partikel-Klasse erkannt, die in der Luft nicht vorhanden war. In der Statistik bezeichnet man dies als «falsch-positiv».
Die Vor- & Nachteile von maschinellem Lernen
Eine große Stärke des maschinellen Lernens ist gleichzeitig auch eine große Schwäche. Gemeint ist das selbstständige Erkennen relevanter Merkmale aus einem Haufen von Daten. Da ein Modell im Wesentlichen eine Blackbox ist (siehe Abbildung 3), können wir nicht genau feststellen, welche Merkmale es zur Unterscheidung von Klassen gelernt hat. Daher ist es fast unmöglich zu überprüfen, ob eine Klassifizierung sinnvoll ist oder nicht.

Wir haben im Wesentlichen zwei Optionen, um dieses Problem zu beheben.
- Wir können Trainingsbeispiele für alle möglichen Klassen, die in der Luft vorkommen hinzufügen.
- Wir stellen sicher, dass wir dem Algorithmus nur Daten zeigen, für deren Erkennung er trainiert wurde.
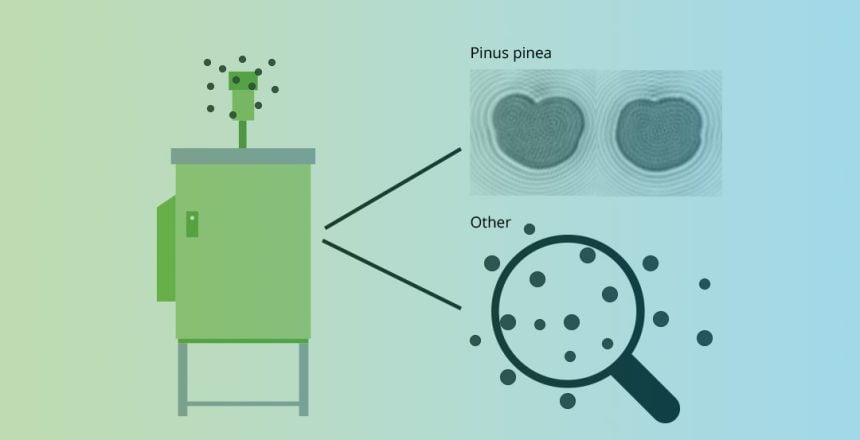
In den meisten Fällen ist es nicht möglich, einen vollständigen Satz von Trainingsbeispielen für alle Partikeltypen bereit zu haben. Wir müssen daher die Partikel, die wir dem Algorithmus zeigen, einschränken und sicherstellen, dass wir ihm ausschliesslich Daten von Partikeln zeigen, für deren Erkennung er trainiert wurde. Für den Fall der automatischen Pollenidentifikation müssen wir einerseits die Gesamtanzahl Pollen von anderen Aerosol-Partikeln, unterscheiden und andererseits die einzelnen Pollentypen voneinander unterscheiden. An diesem Punkt kommt nun der Vorfilter zu Einsatz, der uns bei der Trennung von Pollen zu anderen Aerosol-Partikeln, Abhilfe verschafft.
Der Pollen-Vorfilter
Der Ansatz für die Vorfiltrierung von Pollen und anderen Aerosol-Partikel ist ziemlich einfach. Pollen haben in der Regel eine kompakte, kugelförmige Form, die im grossen Gegensatz zu anderen Aerosolpartikeln steht. Allein mit dieser Eigenschaft können bereits 98 % der anderen Aerosol-Partikel aussortiert werden. Es gibt jedoch Ausnahmen, auf die wir im Laufe der Jahre gestoßen sind. Zum Beispiel können Wüstenstaubkörner ebenfalls sehr kugelförmig aussehen. Auch Wassertropfen im Nebel neigen dazu, vollkommen rund zu sein. Für solche Fälle erstellen wir Datensätze mit diesen Partikeltypen und trainieren den Algorithmus zusammen mit den Pollenklassen. So ist zum Beispiel jedes unserer Pollenmodelle, das derzeit im Einsatz ist, auf die Unterscheidung von Wassertropfen trainiert.
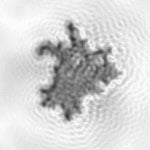
Um die Rundheit oder Kompaktheit eines Partikels zu bestimmen, verwenden wir das so genannte «Soliditätsmaß» wie in Abbildung 4 erklärt wird..
Dabei wird die Fläche des Partikels mit seiner konvexen Hülle verglichen. Eine perfekte Kugel hat einen Wert von eins. Bei Pollen haben wir festgestellt, dass die «Solidität» in der Regel deutlich über 0,9 liegt, was derzeit der Standardwert für den Vorfilter ist. Staubkörner hingegen haben deutlich niedrigere Werte. Das Partikel in Abbildung 5 hat zum Beispiel eine «Solidität» von 0.6.
Weitere Kennwerte zu morphologischen Partikeleigenschaften von SwisensPoleno, können sie hier nachlesen
Zusätzlich zu diesem Kompaktheitsfilter haben wir weitere Kennwerte, welche einem Pollenkorn zugeordnet werden können. Wir wissen, dass Pollen in einem bestimmten Größenbereich liegen. Dies wird entweder von einem Experten bestimmt oder wir überprüfen die Trainingsdaten und suchen nach der minimalen Größe.Diese zwei einfachen Bedingungen (Kompaktheit & Grösse) sind erstaunlich effektiv und leicht zu implementieren. Um ein aktuelles Beispiel zu nennen, werden genau diese Filter unteranderem für das Automatische Pollen Messnetz von MeteoSchweiz eingesetzt.
Für andere Länder und Regionen müssen diese Werte eventuell angepasst werden. Gleichzeitig empfehlen wir für die relevanten Pollen in dieser Region, frische Trainingsdaten aufzunehmen.
Wir hoffen, dass Sie nun besser verstehen, wie und warum wir einen Vorfilter für die automatische Identifikation von Aerosol-Partikel und Pollen anwenden. Lassen Sie es uns wissen, wenn Sie mehr Einblick in einen Aspekt dieses Themas haben möchten. Gerne geben wir Ihnen weiterführende Informationen.